Neta Art XL V2.0 - Better Dynamics, Anatomy and Epic Scenes
First release address:
Civitai - https://civitai.com/models/410737
Liblib - https://www.liblib.art/modelinfo/55b06e35dd724862b3524ff00b069fe8

I. Overview
-
We have updated Neta Art XL V2.0. Comparing to version 1.0, we have optimized the character’s posture dynamics, further strengthened hand stability, and the model is very good at telling stories with atmospheric epic scenes.
-
Main motivation:
-
In V1.0, the default poses generated by our characters are relatively fixed, while the new version enhances the sense of dynamics, diverse character camera expressions, and more precise prompt control.
-
On the basis of increasing more stylistic diversity, more stable anatomy has been maintained, especially the probability of having five fingers (instead of four or six) on the hands is now higher!
-
Further training methods for issues such as Rectified Flow and Noise Offset have been better deployed. The current picture has a strong sense of epic, and can now show very bright and dark scenery (as shown in the figure below).
-

{
"prompt": "1girl, full moon, moonlight shadow, cinematic lighting, battle field, fighting armies, castle, warriors around, waving, looking at viewer, Heterochromatic pupil, sitting on a cliff, very dark, epic scene, inferno, cowboy shot, depressed, angel wings, solo, white long hair, wings bangs, beautiful color, amazing quality,",
"negative_prompt": "nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, rating: sensitive, low contrast, signature, flexible deformity, abstract, low contrast, ",
"resolution": "1344 x 768",
"guidance_scale": 8,
"num_inference_steps": 28,
"sampler": "Euler a",
"use_lora": null,
"use_upscaler": {
"upscale_method": "bislerp",
"upscaler_strength": 0.65,
"upscale_by": 1.5,
"upscale_cfg": 11,
"new_resolution": "2016 x 1152"
}
}Prompting guide
In Neta V2, we re-trained based on ArtiWaifu Diffusion V1.0 (AWA1). Therefore, we used the prompt order summarized in ArtiWaifu:
Tag order: art style ( by xxx ) - > character ( 1 frieren (sousou no frieren) ) - > race (elf) - > composition (cowboy shot) - > painting style ( impasto ) - > theme (fantasy theme) - > main environment (in the forest, at day) - > background (gradient background) - > action (sitting on ground) - > expression (expressionless) - > main characteristics (white hair) - > other characteristics (Twintails, green eyes, parted lips) - > clothing (wearing a white dress) - > clothing accessories (frills) - > other items (holding a magic wand) - > secondary environment (grass, sunshine) - > aesthetics ( beautiful color , detailed ) - > quality ( best quality) - > secondary description (birds, clouds, butterflies)





Negative prompt: ( worst quality : 1.3), low quality , lowres , messy , abstract, ugly, disfigured, bad anatomy, draft, deformed hands, fused fingers, signature, text, multi views
Sampler parameters: Eular a is recommended as default for 28 + inferences.
Neta Art XL 2.0 still supports a very wide range of CFGs (3-20). But this time we have re-aligned the standard CFG of the model to the normal range of 7-9 for everyone to switch experiments.
II. New style recommendations
We have updated some style activation words and optimized the training. To avoid too much confusion with the original meaning of these words, it is now recommended to add a style suffix when activating.
| Classic anime(Activation word: anime coloring) | Optimize thick impasto(Activating word: oil-pasto style) | Semi-thick impasto(Activation word: half-impasto style) | Heavy training 2.5d(Activation word: 2.5d style) |
|---|---|---|---|
 |  |  |  |
Neta Art XL 2.0 updates a number of special artists, activated using the by xxx tag.
| by chi4 | by hitomio16 | by ikky | by ciloranko | by yomu |
|---|---|---|---|---|
 |  |  |  |  |
You can refer to https://civitai.com/models/435207/artiwaifu-diffusion to find more supported artists
III. Better role dynamics
| 1girl, jack-o’ challenge | 1girl, upside-down | 1boy, harry potter, magic wand, amazing quality | 1girl, yoimiya(genshin impact), by as109, by antifreeze3, by sho (sho lwlw), by junny | |
|---|---|---|---|---|
| Neta Art XL V2.0 |  |  |  |   |
| Neta Art XL V1.0 |  |  |  |   |
| Original question | Incoordination of limbs | Not distinguishing hands and feet | Scenes are more templated | V1’s stylization is not obvious and more like a fixed character illustration, while V2’s characters are very vivid and lively |
IV. Epic scenes



V. Training strategies
Model Training is divided into three stages.
-
Rough practice: Teach models basic knowledge and concepts of the second dimension.
Learning Rate: Constants 1e-5 (unet), 7.5e-6 (text encoder)
Equivalent batch size: 96
Optimizer: AdaFactor (False relative_step, scale_parameter and warmup_init)
Noise-free offset
Time step sampling: LogitNormal (ln3,1)
Minimum signal to noise ratio: 5
Note: Since the basic model has most of the prior knowledge, this stage is skipped in actual training. -
Concept Reinforcement: This stage teaches and reinforces all the concepts that the model needs to learn, including artists and characters with less data. The core strategy is data weighting - increasing the weight of data with less data, that is, the number of times it is repeatedly trained in a single epoch, and supplemented with other strategies to help concept learning, such as randomly removing core features of characters.
The training parameters for the concept reinforcement stage are exactly the same as those for rough practice. -
Refinement: This stage uses data with quality ratings of best and amazing to continue fine-tuning the model, freezes the text encoder, enables label randomization algorithm, adds noise offset of 0.0357, and uniformly samples time steps during training.
Learning Rate: Constants 2e-6 (unet), 1e-6 (text encoder)
Equivalent batch size: 48
Optimizer: AdaFactor (False relative_step, scale_parameter and warmup_init)
Noise offset: 0.0357
Time step sampling: uniform distribution (same as normal training)
Minimum signal to noise ratio: 5
VI. Terms of Use
The model was developed by Nieta Lab : Neta.art Lab - https://civitai.com/user/neta_art
Collaborative participants:
-
Chenkin: https://civitai.com/user/Chenkin
-
Bo Dai: https://daibo.info/
Terms of Use:
-
The model was developed from ArtiWaifu and AAM XL using [Fair AI Public License 1.0-SD]
-
If you later modify, merge, or develop the model again, you need to open source the subsequent derived model .
VII. Summary and Outlook
Neta Art DiT follow-up training. Stay tuned and test our product for free: https://neta.art .
Bilibili: https://space.bilibili.com/505727005
RED: https://www.xiaohongshu.com/user/profile/63f2ebf2000000001001e206
Twitter: https://twitter.com/netaart_ai
Civitai:https://civitai.com/user/neta_art

Following is backlog for V1
This is the English Release Note for Neta Art XL V1.0, 中文翻译的发布报告请查看:
Neta Art XL V1.0 发布 - 最好用的 XL 二次元基础模型
Civitai - https://civitai.com/models/410737
Huggingface - https://huggingface.co/neta-art/neta-art-xl-1.0
SeaArt - https://www.seaart.me/models/detail/72e3e0818dd822314296be910b7a88b3

{
"prompt": "1girl, by yoneyama mai, by maimuro, pseudo-impasto, waving, Heterochromatic pupil, (sitting on a neon planet), cowboy shot,amazing quality, depressed, angel wings, solo, white long hair, wings bangs, provocative, cosmic background, cables and wires contrast aesthetic, beautiful color, (amazing quality:1.5), masterpiece",
"negative_prompt": "nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, rating: sensitive, low contrast, signature, flexible deformity, abstract, low contrast, ",
"resolution": "1344 x 768",
"guidance_scale": 8,
"num_inference_steps": 28,
"sampler": "Euler a",
"use_lora": null,
"use_upscaler": {
"upscale_method": "bislerp",
"upscaler_strength": 0.65,
"upscale_by": 1.5,
"upscale_cfg": 11,
"new_resolution": "2016 x 1152"
}
}I. Overview
-
Introducing Neta Art XL V1.0, the easiest-to-use SDXL Anime model so far.
-
Keywords: Best Character Coverage, Vivid storytelling, Diverse styles, Stable anatomy.
-
Major motivation:
-
Better stability and anatomy for character visual storytelling purpose:
-
Ordered prompt guide for model to easier follow prompts;
-
A very good balance between better knowledge and stability.
-
-
Maintain a high ceiling standard for aesthetics across versatile anime art styles, while keeping the baseline of output appealing for general users.
-
Huge knowledge base, less loras for characters / styles / artists, so we make better use of static model acceleration techniques.

Characters Coverage - refer to both A3.1 + AIDXL lists in the following json file
Prompting Guide
To avoid possible ambiguity in text prompt, and leave room for very complicated scene such as multi-character, we found enforcing an ordering in prompts leads to better instruct-following behaviors (Learn from NAI3 / Animagine3 / AIDXL). Specifically, we use the following order in Neta Art XL:
Tag Order: subject (1boy / 1girl) -> character (a girl named frieren from sousou no frieren series) -> Artist trigger (by xxx) -> race (elf) -> composition (cowboy shot) -> style (impasto style) -> theme (fantasy theme) -> main environment (in the forest, at day) -> background (gradient background) -> action (sitting on ground) -> expression (is expressionless) -> main characteristics (white hair) -> body characteristics (twintails, green eyes, parted lip) -> clothing (wearing a white dress) -> clothing accessories (frills) -> other items (a cat) -> secondary environment (grass, sunshine) -> aesthetics (beautiful color, detailed, aesthetic) -> quality ((best quality:1.3))





More examples: Neta Art XL V1.0 生成样例(对外分享)
Negative prompts: (worst quality:1.3), low quality, lowres, messy, abstract, ugly, disfigured, bad anatomy, draft, deformed hands, fused fingers, signature, text, multi views
Sampler: Eular a normal as default, 28+ steps recommended.

One additional merit of Neta Art XL is that it supports a very wide range of CFGs (5 - 20 compared to 7 - 9 of previous models). While we empirically found higher CFG leads to more details and higher contrast, generally CFG 9 - 14 (important!) can be used for best results.
II. Highlight: Style Versatility
We carefully selected 13 style keys with good orthogonality and are commonly used in many scenarios, justified by usage data from Nieta AI (30M+ generations).
Having orthogonal styles means each style is effectively different from the others, allowing you to easily combine and create new styles without interference.
| impasto | Flat color | Pseudo-impasto | Celluloid |
|---|---|---|---|
 |  |  |  |
| 2.5d | line-sketch | Pixel art | Korean Anime (trigger: kri-ani) |
|---|---|---|---|
 |  |  |  |
| Cute (trigger word: chibi) | Chinese Traditional (trigger word: gufeng) | Dark Style (trigger word: helltaker maker) | Meme Sticker (trigger word: bqb) |
|---|---|---|---|
 |  |  |  |
| Vibrant (trigger word: tiaotiaotang) | Remix: Gufeng + Pixel Art + Chibi | Remix: 2.5d + Korean Anime + line-sketch |
|---|---|---|
 |  |  |
Neta Art XL also includes a long list of artist styles, activated
through by xxx clause.
| By ask | By mochizukikei | By ziyun | By dino | By eku uekura |
|---|---|---|---|---|
 |  |  |  |  |
| By hata | By poire | By rella | By fuzichoco | By void |
|---|---|---|---|---|
 |  |  |  |  |
Please refer to https://civitai.com/models/124189/anime-illust-diffusion-xl for a complete list of supported artists.
III. Expression, Posing, and Camera Angles
| Face pinching, :o | Double v | Wiping tears | jumping-from-rooftop |
|---|---|---|---|
 |  |  |  |
Compared to other models, Neta excels at maintaining stability, prompt following ability, and anatomical accuracy even with challenging poses or camera angles that would cause degradation in other models. We compared our results to the second-best candidate models to highlight Neta’s advantages in these areas:
| 1girl, running, grassland, closeup | Nahida, 1girl, female, solo, on side, (looking at viewer), forest, flora | 1boy, lie on stomach | 1boy, neuvillette (genshin impact), genshin impact, solo, (blue down jacket, white pants, brown snow boot, put both hands in the pocket:1.2), looking at viewer, snowy, ground with white snow and footprint, from above | 1girl, arima kana, oshi no ko, solo, idol, idol clothes, one eye closed, red shirt, black skirt, black headwear, gloves, stage light, singing, open mouth, crowd, smile, pointing at viewer, masterpiece, best quality | |
|---|---|---|---|---|---|
| Neta Art XL V1.0 |  |  |  |  |  |
| AnimagineXL3.1 |  |  |  |  |  |
| Fixed Issues | Figure not stable | Overfitted poses | Girls always appear | Not “looking at viewer” | Both great work! |
IV. Multi-Character Scenes
Examples of group scenes with multiple characters




V. Text & Typography
Neta Art XL demonstrates good ability to keep poster-like text in good success rate.



VI. Training
Training workflow:
The model was trained based on AAM V10, with Neta dataset and AIDXL dataset; most regularization dataset are from AIDXL best quality data; The merge only occurs in final step: which we conclude crystal clearly that it’s “We merged 0.05 CLIP and 0.15 UNet input layers from Animagine 3.1”.
-
Data annotation combining multiple sources (Original prompt, CogVLM captions, WaifuTagger tags)
-
Post-processing techniques like semantic deduplication and hierarchical tag organization
a. Semantic Deduplication: This removed redundant tags by intelligently detecting when a higher-level tag (e.g. very long hair) semantically covered a lower-level one (e.g. long hair).
b. Tag Layering Algorithm: Tags were organized into hierarchical layers based on their priorities and related semantics (eg. by wlop influence the whole picture styling, while frills influence a small fraction). More dominant tags were placed in higher layers to prioritize their influence during training.
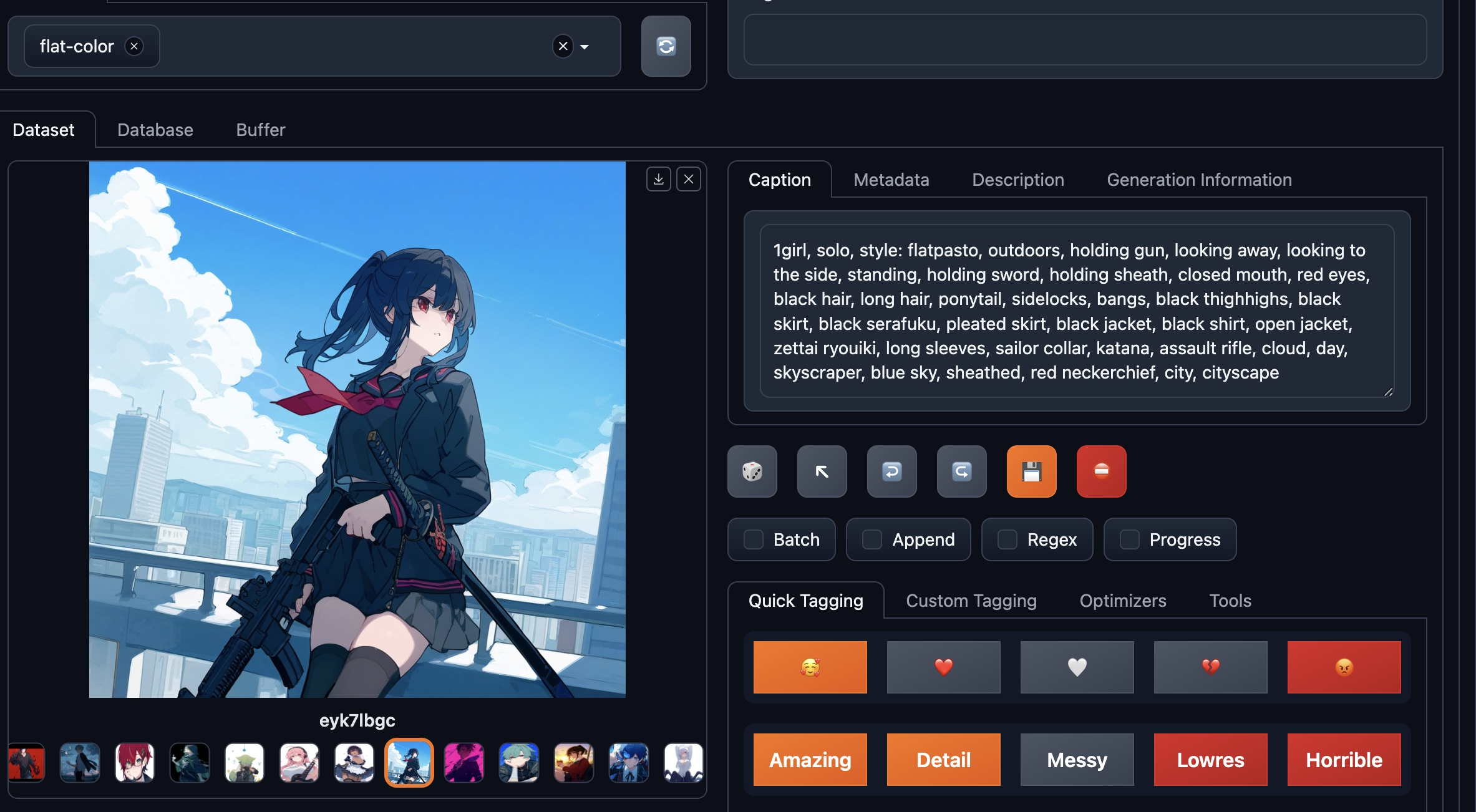
Dataset management tool from https://github.com/Eugeoter/waifuset
-
Using high-quality regularization data from AIDXL: High-quality regular datasets with “best” and “amazing” quality ratings from AIDXL. These datasets are manually selected and come with detailed annotations and natural language descriptions.
-
Finetuning on more knowledgeable base models like AAM, blending with AnimagineXL 3.1 Character Knowledge.
Challenges Faced:
-
Imbalance in learning different styles
-
Poor generalization for some styles to diverse scenes
-
Lack of details/texture in generations
-
Trigger word overlap with base model knowledge
Solutions Explored:
-
Data reweighting to balance style learning, and supplement diverse data per style.
-
Tuning sampling hyperparameters like minimum gamma and rectified flow. Rectified Flow is a training parameter that increases the sampling frequency in the middle time steps but weakens the weight of the model’s learning ability for small noises in the low time steps. This technique helps to improve the model’s ability to restore styles but requires the use of a knowledge-rich base model.
-
Randomizing / drop off trigger words during training.
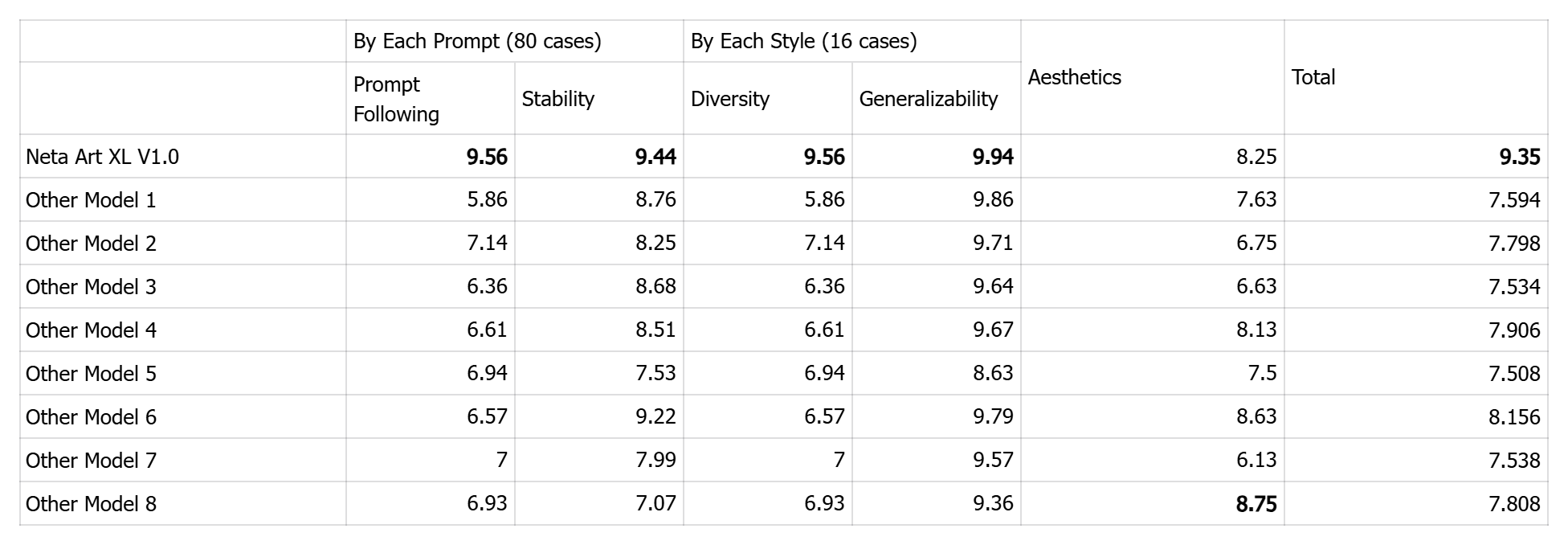
VII. Evaluation(Not going to be a Research Paper, but useful for the team)
We know what CCIP and DPG-Bench are, but after a simple test we don’t think it fits our purpose very well, so we went with user study.
Nine models are evaluated using 16 styles (some unique to Neta Art, it not going to be very research oriented, thus biased :P) and 80 prompts. Each prompt generates 3 samples with different aspect ratios, resulting in an XYZ plot (Generated from https://github.com/talesofai/comfyui-browser).

XYZPlot of 3,840 samples, just for one-time evaluation. Here’s an online Example.
Evaluation is done on a 10-point scale across four axes under objective counting rules:
-
Prompt Following: Points deducted for every 5 images unrelated to the prompt.
-
Stability: Points deducted for distortions or breakages in heads, hands, feet, or composition.
-
Diversity: Points deducted for poor style restoration within each style column.
-
Generalizability: Points deducted for poor semantic generalization within each style column.
Additionally, 10 top model trainers provide subjective scores for Aesthetics, with an average calculated for each model.
VIII. License
Developed with ❤️ by: Neta.art Lab - https://civitai.com/user/neta_art
In collaboration with:
-
Chenkin: https://civitai.com/user/Chenkin
-
Bo Dai: https://daibo.info/
Thanks to:
https://blog.novelai.net/introducing-novelai-diffusion-anime-v3-6d00d1c118c3
https://cagliostrolab.net/posts/animagine-xl-v3-release
https://civitai.com/models/269232/aam-xl-anime-mix
https://civitai.com/models/124189/anime-illust-diffusion-xl
https://github.com/deepghs/waifuc
Model type: Diffusion-based text-to-image generative model
License: We merged 0.05 CLIP and 0.15 UNet input layers from Animagine 3.1, thus [Fair AI Public License 1.0-SD]
IX. Conclusion and Future Work
Shortcomings:
-
Some characters are underfitted.
-
Styles are not activated well with long prompts.
-
Certain styles appear grayish at low CFG and short prompts. Partly explained in https://civitai.com/articles/4969.
Future Work:
-
Prepare larger training sets and more knowledge-based data to improve character, style, and detail handling.
-
Welcome others to join discussions, provide suggestions, and contribute to model advancement.
Neta Art XL 2.0 is on the way. Stay tuned with us, and test our product for FREE: http://neta.art/
Discord: https://discord.gg/AtRtbe9W8w
Twitter: https://twitter.com/netaart_ai
Civitai:https://civitai.com/user/neta_art
