
Ⅰ. Overview
TL;DR
Neta Lumina is a high-quality anime-style text-to-image model trained by Neta.art Lab on the basis of Lumina2. The preliminary result is a compelling model with powerful comprehension and interpretation abilities, ideal for illustration, posters, storyboards, character design, and more. We not only open source model weights, but also how we built training pipeline, and part of the datasets & captions.
Ⅱ. Introduction
Our objective is to deliver a Flux-grade text-to-image system built for anime content.
Why Choose Lumina2 as Base Model?
Maturity matters: Autoregressive pipelines are still shaky in tools and infra, so we stuck with the more battle-tested DiT family.
We then compared SD 3.5, Flux, HiDream, Sana, and Lumina 2 wins on these fronts:
-
Compact model size → faster training, lower GPU cost.
-
Newer architecture → cleaner codebase and better long-term head-room.
-
Stable on anime data → smoother convergence, fewer artifact spikes.
Contribution
Neta Lumina has achieved:
-
Optimized for diverse creative scenarios such as Furry, Guofeng (traditional-Chinese aesthetics), pets, scenery shots, etc.
-
Balanced data for under-represented scenes — male, non-human entities, objects in hand, etc.
-
Wide coverage of styles, from popular to niche concepts. (Still support Danbooru tags!)
-
Accurate natural-language understanding with excellent adherence to complex prompts.
-
Native multilingual support, with Chinese, English, and Japanese recommended first.
Our Product Showcase
This section highlights various aspects of our product and capabilities.
Explore the different categories to see our work in action.
Ⅲ. Related Work
We gratefully acknowledge the Alpha-VLLM team: their open-sourced Lumina-Image 2.0 and Lumina-Next frameworks constitute the technical bedrock of this project, and our present level of performance would not have been possible without their pioneering work.
- Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
- Lumina-Next: Making Lumina-T2X Stronger and Faster with Next-DiT
Ⅳ. Training Strategy & Roadmap
Phase 0 · Pilot Training
We seeded the pipeline with a 500K-image generic-illustration corpus. The resulting checkpoint proved the model could already render baseline anime aesthetics, yet it revealed two critical shortcomings:
- Stylistic precision — it struggled to consistently capture fine-grained anime sub-styles.
- Anatomical accuracy - frequent errors in limb proportions and dynamic motion.
This diagnostic run validated the feasibility of the approach.
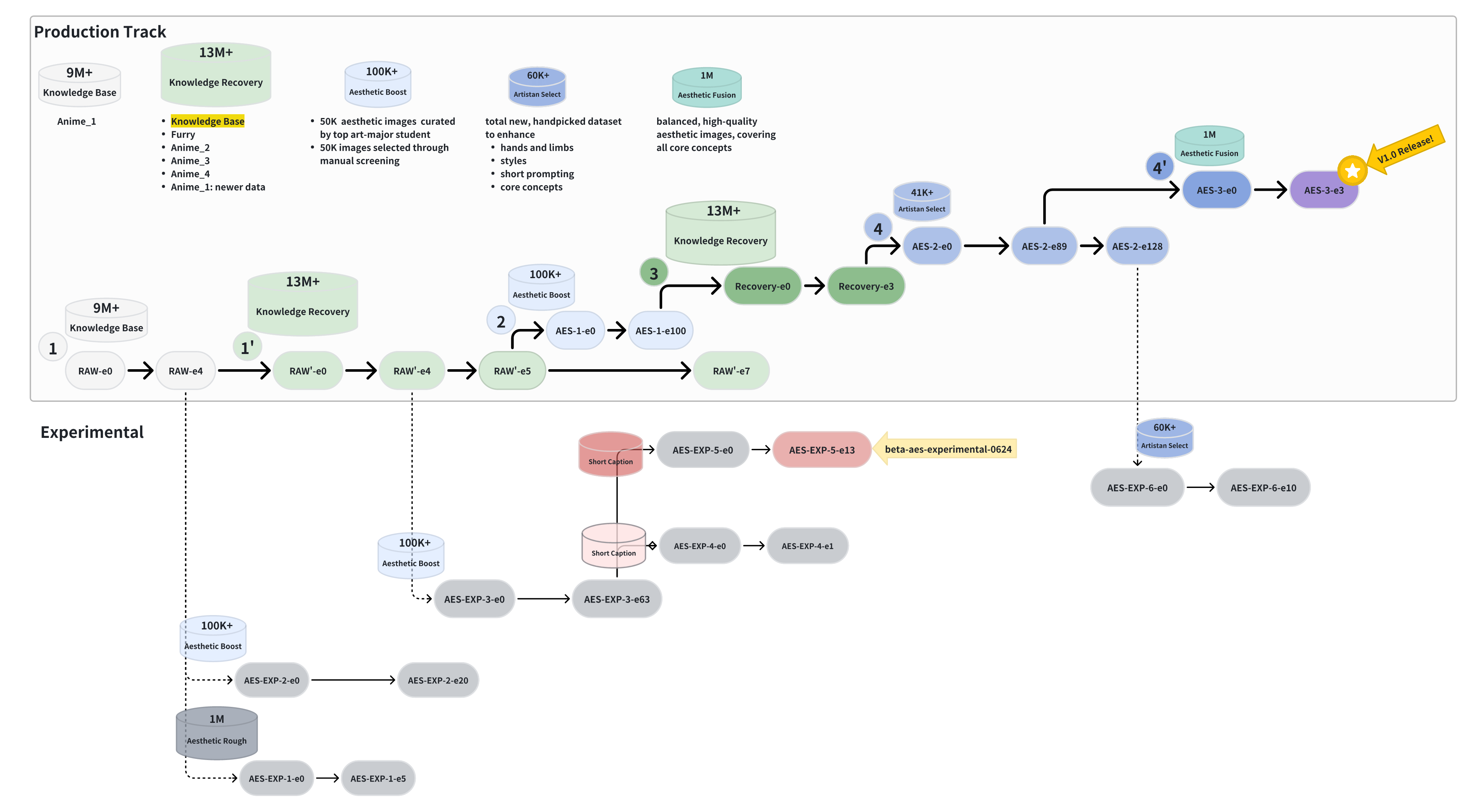
Key Findings
- 4-Phase Curriculum Improves Both Knowledge Coverage and Aesthetics
We adopted a large-small-large-small training curriculum:
- Phase 1 · Large-1, 9M then 13M samples, Knowledge Base - broad knowledge acquisition.
- Phase 2 · Small-1, 100K high-aesthetic set, Aesthetic Boost - boosts aesthetic performance and short prompt compliance but triggers partial catastrophic forgetting.
- Phase 3 · Large-2, 13M samples, Knowledge Recovery - restores lost knowledge while retaining Phase 2 aesthetic gains
- Phase 4 · Small-2, 60K hand-picked set, Artisan Select - fine-grained polish for micro-details, coverage of core concepts, art style aesthetics, and ultra short prompts.
This alternating schedule outperforms the conventional large-then-small fine-tune.
- Timing of High-Complexity Aesthetic Data Is Critical
Introducing a 100k high-complexity masterpiece subset too early (i.e., before the knowledge is fully consolidated) improved upper limit aesthetics but degraded stability. We attribute this to the subset's artistic skills such as exaggerated lighting, unconventional compositions, and even on-purpose flaws. which the model could not yet generalize to. We fixed those degradation by introducing high aesthetic yet less complex subset in Phase 4.
Ⅴ. Dataset
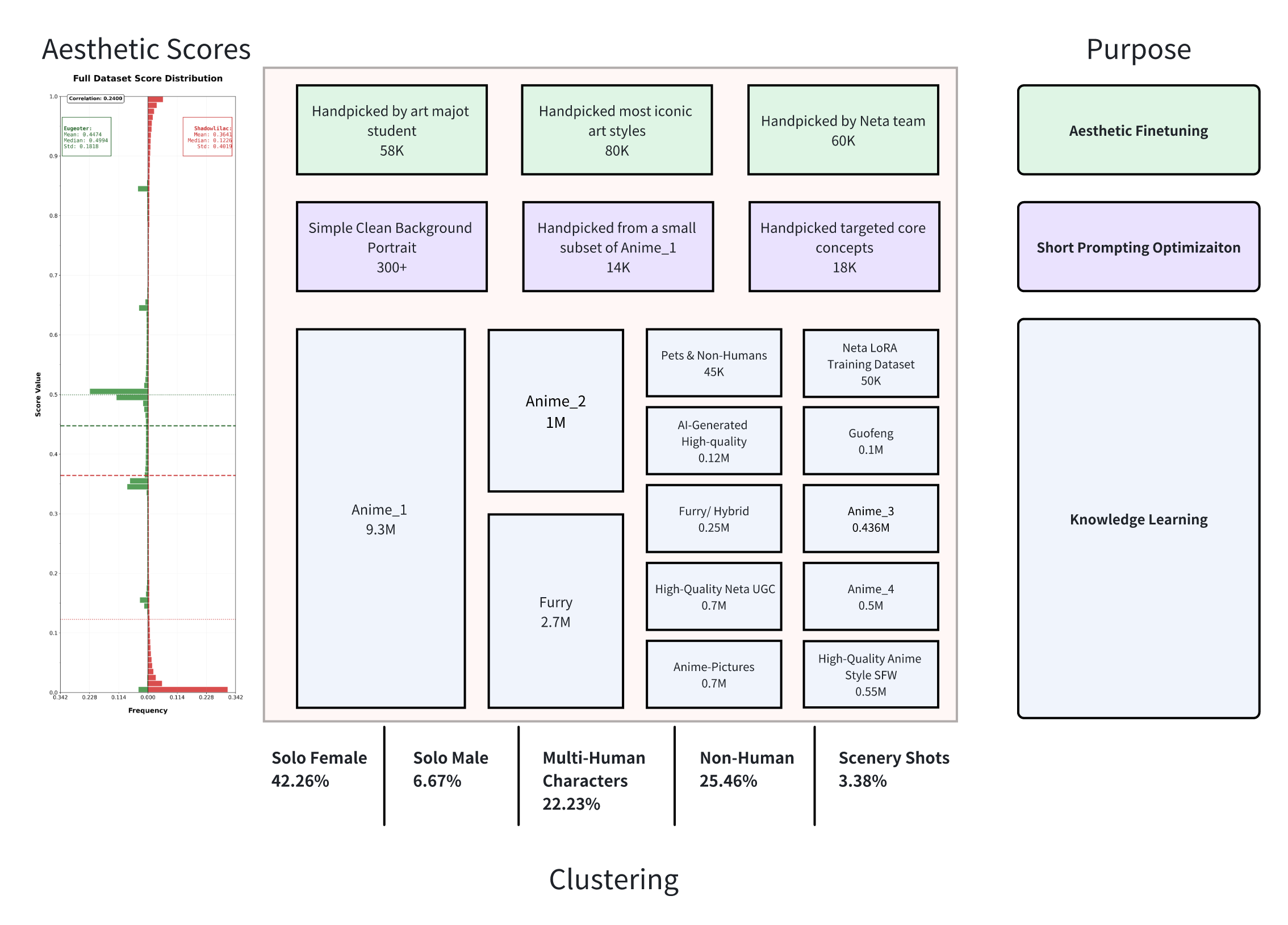
Data Governance
Deduplication
- We apply a dual-check system—MD5 hash plus pHash—to eliminate duplicate images across all sources.
Quality Filtering
-
Resolution tiering: reject any image whose shorter edge is < 512 px.
-
Corruption screening: automatically removes damaged files.
-
Aspect-ratio guard: drop images with width-to-height (or height-to-width) ratios > 4:1.
Distribution
-
Construct a weighted sampling matrix to harmonize contributions from multiple data sources.
-
Prioritize “core anime” datasets.
-
Supplement with “near-anime” datasets to broaden stylistic coverage.
-
Keep adding datasets based on test results.
During data cleaning we discovered that 37% of the raw dataset was made up of strictly NSFW material. Left unbalanced, this skew would push the model's outputs away from the tastes of our target audience.
Action taken - We cross-checked Neta's data and introduced an * aesthetic-balancing
- sampling strategy, ensuring a distribution that matches actual user preferences.
Aesthetic Scoring
We employ two independent, open-source aesthetic scoring models to systematically evaluate visual quality:
-
Aesthetic-Shadow: https://huggingface.co/shadowlilac/aesthetic-shadow
-
Waifu-Scorer v4 (beta):https://huggingface.co/Eugeoter/waifu-scorer-v4-beta
On the 13M+ images dataset, the Pearson correlation between the two aesthetic scoring models was only 0.24, indicating that each model predominantly captures distinct and complementary aesthetic features. The full distribution chart can be found in earlier section.
By employing an intersection-based filtering strategy—selecting images that score highly in both models—we effectively mitigated the biases inherent in any single scoring model. This allowed us to efficiently generate a large pool of high-quality aesthetic candidates, forming a critical foundation for constructing our Phase 2 training dataset.
Clustering & Balancing
We cluster datasets in 26 dimensions
NO. | Dimension | Total Categories | Concentration Index | Gini Impurity | Dominant Class | Dominant Share | Least‑Represented Class | Imbalance Level |
|---|---|---|---|---|---|---|---|---|
1 | ArtStyle | 298 | 0.335 | 0.665 | Cel‑shaded | 54.6 % | Oil‑painting style | Slightly |
2 | ColorTemperature | 26 | 0.666 | 0.334 | Warm | 80.5 % | Blue | Severely |
3 | Lighting | 66 | 0.594 | 0.406 | Natural | 74.9 % | No lighting | Moderately |
4 | SaturationLevel | 8 | 0.417 | 0.583 | Medium | 48.3 % | Other saturation levels | Moderately |
5 | ContrastLevel | 8 | 0.508 | 0.492 | Medium | 59.1 % | Other contrast levels | Moderately |
6 | Composition | 696 | 0.666 | 0.334 | Central framing | 81.3 % | Tilted perspective | Severely |
7 | FramingDistance | 100 | 0.403 | 0.597 | Close‑up | 51.5 % | Bird’s‑eye view | Moderately |
8 | LineWeight | 14 | 0.609 | 0.391 | Bold outlines | 74.5 % | Medium outlines | Severely |
9 | CameraAngle | 98 | 0.857 | 0.143 | Eye‑level | 92.4 % | High‑mid angle | Extremely |
10 | SubjectOrientation | 95 | 0.482 | 0.518 | Frontal view | 57.6 % | Three‑quarter frontal | Moderately |
11 | SubjectGender | 124 | 0.680 | 0.320 | Female | 81.9 % | Infant | Severely |
12 | SubjectCount | 16 | 0.490 | 0.510 | 1 subject | 65.7 % | Other counts | Moderately |
13 | MotionState | 10 | 0.766 | 0.234 | Static | 87.0 % | Still‑series variants | Severely |
14 | Medium | 349 | 0.820 | 0.180 | Illustration | 90.3 % | Photomanipulation | Extremely |
15 | EmotionalTone | 439 | 0.190 | 0.810 | Happy | 28.6 % | Joy/Anger mix | Relatively |
16 | NarrativeGenre | 131 | 0.328 | 0.672 | Miscellaneous topics | 48.7 % | Street art | Slightly |
17 | Setting | 190 | 0.391 | 0.609 | No specific setting | 58.8 % | Island | Slightly |
18 | TimeOfDay | 56 | 0.512 | 0.488 | Daytime | 64.6 % | Sunrise | Moderately |
19 | SubjectAgeGroup | 42 | 0.419 | 0.581 | Adolescent | 46.0 % | Mixed ages | Moderately |
20 | AttireStyle | 1061 | 0.164 | 0.836 | Modern casual | 30.4 % | Angel attire | Relatively balanced |
21 | WeatherCondition | 30 | 0.585 | 0.415 | Clear | 72.5 % | Hot | Moderately |
22 | BackgroundComplexity | 25 | 0.269 | 0.731 | Minimal solid colour | 36.3 % | Dark | Slightly |
23 | HeadToBodyRatio | 115 | 0.244 | 0.756 | 1 : 6 | 42.2 % | Irregular | Slightly |
24 | WatermarkPresent | 6 | 0.616 | 0.384 | None | 74.1 % | Watermarked set | Severely |
25 | TextPresent | 6 | 0.544 | 0.456 | None | 64.8 % | Text‑series images | Moderately |
26 | ImageOrientation | 144 | 0.485 | 0.515 | Landscape | 54.6 % | Split format | Moderately |
To address data imbalance while preserving aesthetic integrity, we leveraged model-inferred aesthetic scores and applied a resampling strategy to curate a 500K-image subset, balanced across five key dimensions: ArtStyle, SubjectGender, SubjectCount, NarrativeGenre, and Medium.
Using our Panel Data Tool, a team of experts rapidly curated the subset to its top 10%, producing a 50K-image corpus that is optimized for human preference alignment, class distribution, and anime aesthetic excellence.
Ⅵ. Pipelines
Labeling Framework
High-quality labels unlock the full value of image data, so we built a multi-dimensional and dynamic pipeline.
Layered Labeling Strategy
To balance scale and precision we combine three sources of tags:
Layer | Source | Purpose |
|---|---|---|
VLMs | Google Gemini, ByteDance Doubao | Rich natural‑language captions and scene descriptions |
Taggers | WD‑14 Tagger, JoyTag | Rapid extraction of Danbooru‑style object tags |
User Prompts from Neta App | user text-to-image inputs | Human Prompting alignment |
Dynamic Caption Engine
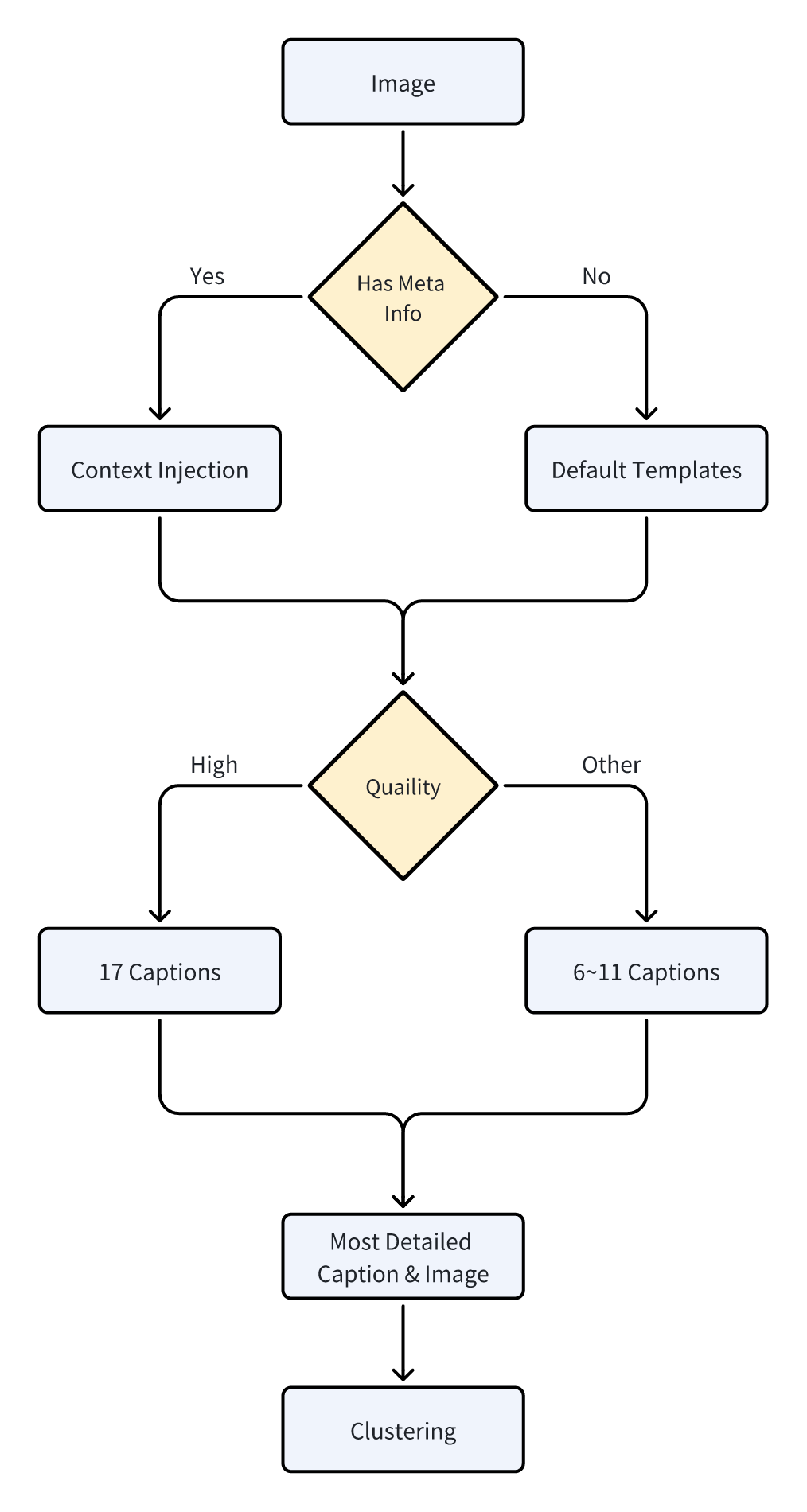
We used 20+ different prompts for better caption diversity and coverage. Our caption engine produces 6-17 alternative captions for every image, each with a different structure or focus. English: Chinese: Japanese ≈ 10:3:1
Key tricks:
-
Context injection – Known metadata is fed into the prompt so VLMs label more accurately.
-
Short‑Prompt Optimization – VLMs sometimes stumble on very short prompts. We therefore run a compression pass: use VLMs to extract core concepts from long captions, distill them into concise tags, and store both long and short versions. This boosts generation quality in “one‑liner prompt” use‑cases.
CLASS PromptBuilder
FUNCTION __init__()
CONNECT to MongoDB
SET tag_collection ← db["dan"]["tags"]
END FUNCTION
FUNCTION build_prompt(
style, tags,
lang = "en", ref_info = NULL, extra = NULL
) → DICT
// Core positive prompt
positive ← f"{style}, {tags}"
IF ref_info ≠ NULL
positive ← positive + " — " + ref_info
END IF
IF extra ≠ NULL
positive ← positive + ", " + extra
END IF
// Simple negative prompt
negative ← "low quality, blurry"
RETURN {
"positive": positive,
"negative": negative,
"language": lang
}
END FUNCTION
END CLASS
What the Output Looks Like
For each image, we store a JSON file that contains all of its captions for easy usage. An example:

{
"gemini_caption_v10": {
"master_player_detailed_caption_en": "A highly detailed digital painting in a vibrant anime art style, featuring a single female character, an anime girl, with long, flowing light blonde hair and striking pink-magenta eyes, lying on her side on a wet, light blue tiled floor. She is dressed in a classic Japanese school sailor uniform, consisting of a white long-sleeved shirt with a dark blue collar adorned with white stripes, a prominent, vibrant red bow tied at the neck, and a dark blue pleated skirt. Her expression is subtly melancholic and vacant, with a hint of sadness in her downcast gaze. Numerous small, bright yellow rubber ducklings with simple blue eyes and orange beaks are scattered abundantly around her, some partially submerged in glistening water puddles that reflect the soft light on the reflective, tiled floor. The composition is a wide-angle shot with a low perspective, capturing her full body extending from the left-center to the right-center of the frame. Many ducklings populate the blurred foreground and midground, creating a shallow depth of field, emphasizing the girl as the main subject. Soft, diffused overhead lighting illuminates the entire scene, casting gentle, subtle shadows and creating bright, ethereal specular highlights on the wet surfaces, the ducklings, and a luminous glow around her hair. The dominant color palette consists of cool light blues and desaturated greys for the background and floor, sharply contrasted by the warm yellows of the ducklings, the vibrant red of her bow, and the intense pink of her eyes. The atmosphere is serene, quiet, and deeply contemplative, with a dreamy, slightly melancholic, and whimsical mood. Highly detailed, 8K, high resolution, soft focus, volumetric lighting, intricate details, anime illustration, digital art, clean lines, smooth shading.",
"compress_nl_en": "Anime girl in school uniform with rubber ducks on wet floor.",
"Tag_mix_sentence_en": "I'm looking for an image of a single anime girl with long, wavy blonde hair and striking pink eyes. She's lying on her side on a light-colored, tiled floor, which has visible wet puddles and reflections around her. She's dressed in a white sailor uniform top with a prominent red bow and a dark blue pleated skirt. Her pose suggests a moment of rest or contemplation, with her head slightly tilted and her gaze looking up and to the side. Surrounding her are numerous small, cute yellow chick figures, like rubber ducks, scattered across the wet surface. The scene is lit with soft, bright light, highlighting the wetness on the floor and creating a somewhat melancholic yet serene atmosphere in what appears to be a bathroom or a similar tiled space.",
"compress_tag_en": "anime girl, sailor uniform, wet floor, rubber ducks, blonde hair, melancholic atmosphere",
"Medium_caption_en": "An anime-style girl with long blonde hair and striking pink eyes is lying prone on a light, wet tiled floor, looking directly at the viewer with a slightly melancholic expression. She's dressed in a white sailor uniform shirt with a prominent red bow and a dark blue pleated skirt, with her clothes appearing damp and surrounded by puddles of water. Numerous cute yellow rubber duckies are scattered across the wet surface around her, some blurred in the foreground and background, adding depth to the scene. The lighting is soft and bright, casting gentle reflections on the wet tiles and creating a serene, almost wistful atmosphere.",
"short_summary": "一位金发动漫女孩,有着引人注目的红眼睛,躺在湿漉漉的浅蓝色瓷砖地板上。她身穿白色水手服,搭配深蓝色领子和红色蝴蝶结,周围环绕着许多亮黄色的橡皮鸭。整个场景营造出一种柔和、异想天开且宁静的氛围,地面上散布着反光的积水。",
"designer_caption_en": "A high-angle, full-body shot captures a solitary young female character, rendered in an expressive anime art style, lying prone on a cool-toned tiled floor. Her body is oriented diagonally from the lower left to the upper right quadrant of the composition, creating a dynamic visual line that draws the viewer's eye across the scene. She is surrounded by a multitude of small, yellow rubber duck toys, numbering approximately twenty, which are scattered across the floor, some partially submerged in shallow puddles of water. The perspective provides an intimate, downward gaze, establishing the character's vulnerable position within the space. A shallow depth of field is employed, effectively isolating the central figure and the immediate ducks in sharp focus, while foreground and background elements recede into a soft, photographic bokeh, enhancing the sense of depth and drawing attention to the primary subject. The overall balance is asymmetrical, with the character's diagonal form breaking the horizontal and vertical lines of the environment, lending a subtle tension. The negative space of the tiled floor and a plain, light-grey wall behind her serves to highlight the figure and the vibrant yellow ducks. The lighting is soft and diffused, emanating from an unseen source high and slightly to the left, casting gentle, elongated highlights across the character's blond hair and the glossy surfaces of the water puddles. This soft illumination creates subtle core shadows and delicate cast shadows beneath the ducks and the character's body, providing a sense of form and volume without harsh contrasts, suggestive of a tranquil, perhaps overcast, indoor light. The color palette is predominantly cool, with the muted blues and greys of the uniform and environment providing a serene backdrop for the warm, highly saturated yellows of the rubber ducks and the character's golden hair. Her skin tones are rendered with a soft, peachy warmth, and her eyes are a striking, luminous magenta, offering a vibrant accent that serves as a secondary focal point. The red bow on her uniform provides another powerful, saturated accent, creating a complementary contrast with the cool blues of her sailor collar. Materiality is conveyed through smooth, almost porcelain-like skin, soft, flowing locks of hair, and the crisp, yet rumpled, texture of her white shirt and pleated navy skirt. The rubber ducks exhibit a smooth, matte finish, contrasted by the highly reflective and wet appearance of the water puddles, which show clear, glossy highlights. The atmosphere is one of profound serenity tinged with a delicate melancholy or quiet introspection. The character's closed eyes and prone posture evoke a sense of rest or withdrawal, while the playful presence of the rubber ducks adds a layer of innocent, almost dreamlike, unreality. The scene feels intimate and hushed, inviting quiet contemplation.",
"structured_summary_en": "An anime-style girl with long blonde hair and striking pink eyes is depicted lying on her side on a wet, light-colored tiled floor. She's wearing a Japanese school uniform, consisting of a white shirt with a navy blue sailor collar and a red bow, and a dark blue pleated skirt. Her expression is somewhat pensive or melancholic as she looks towards the viewer. Scattered all around her, and particularly close to her body and hair, are numerous small, adorable yellow rubber ducklings, some appearing to be floating in puddles of water on the reflective floor. The scene is lit softly from above, creating gentle highlights on her hair and the wet surfaces, giving the image a calm and slightly dreamy atmosphere. The composition features the girl diagonally across the frame from top left to bottom right, viewed from a slightly elevated perspective looking down, with the background being a simple light blue-gray wall matching the floor. There is no visible text or logo.",
"midjourney_style_summary_en": "anime girl lying down, long blonde hair spread out, surrounded by numerous yellow rubber ducklings, wearing white sailor uniform, dark blue pleated skirt, large red bow, vibrant pink eyes, wet light blue tiled floor, reflective puddles, soft ambient lighting, serene yet slightly wistful expression, wide shot, high angle",
"chinese_translation": "一位动漫风格的女孩,拥有一头飘逸的金发和引人注目的粉色眼睛,俯卧在光洁、湿漉漉的瓷砖地板上,正视着观者,眼神中带着一丝忧郁。她身穿一件白色水手服上衣,胸前系着醒目的红色蝴蝶结,搭配深蓝色百褶裙,衣服看起来湿漉漉的,周围散布着水洼。无数可爱的黄色小鸭子散落在她周围的潮湿表面,其中一些在前景和背景中模糊不清,为画面增添了景深。光线柔和而明亮,在湿漉漉的瓷砖上投射出柔和的倒影,营造出一种宁静、近乎伤感的氛围。",
"midjourney_style_summary_zh": "一位动漫女孩侧卧着,金色的长发散开,周围环绕着许多黄色小鸭子,身穿白色水手服,深蓝色百褶裙,系着大红色蝴蝶结,有着鲜艳的粉色眼睛,湿漉漉的浅蓝色瓷砖地面,有反光的积水,柔和的环境光,表情宁静但略带忧郁,广角拍摄,高角度俯视",
"designer_caption_ja": "高角度からの全身ショットは、表現力豊かなアニメ風の画風で描かれた、孤独な若い女性キャラクターを捉えています。彼女は、クールトーンのタイル張りの床にうつ伏せに横たわっています。彼女の体は、構図の左下から右上に向かって対角線上に配置されており、視線をシーン全体に引き込むダイナミックな視覚線を形成しています。彼女は、約20個の小さな黄色のラバーダックのおもちゃに囲まれており、その多くは水たまりに部分的に浸かりながら、床に散らばっています。この視点は親密で、見下ろすような視線を提供し、空間内でのキャラクターの脆弱な位置を確立しています。浅い被写界深度が採用されており、中央の人物とすぐ近くのアヒルを鮮明に焦点を当て、前景と背景の要素を柔らかい写真のボケに後退させ、奥行き感を高め、主要な被写体に注意を惹きつけています。全体のバランスは非対称で、キャラクターの対角線的な形が環境の水平線と垂直線を壊し、微妙な緊張感を与えています。タイル張りの床と、彼女の後ろにあるプレーンで淡い灰色の壁のネガティブスペースは、人物と鮮やかな黄色のダックを際立たせています。照明は柔らかく拡散しており、見えない光源が上方のやや左側から発せられ、キャラクターのブロンドの髪と水たまりの光沢のある表面に、穏やかで細長いハイライトを落としています。この柔らかい照明は、アヒルとキャラクターの体の下に微妙なコアシャドウと繊細な落とし影を作り出し、激しいコントラストなしに形態とボリューム感を与え、静かで、おそらく曇りの屋内光を暗示しています。カラーパレットは主にクールで、制服と環境のくすんだ青とグレーが、ラバーダックとキャラクターの金色の髪の暖かく、高度に彩度の高い黄色に対して穏やかな背景を提供しています。彼女の肌の色調は柔らかく桃色の暖かさで表現されており、彼女の目は印象的で輝くマゼンタ色で、二次的な焦点として機能する鮮やかなアクセントを提供しています。制服の赤いリボンは、もう一つの強力で彩度の高いアクセントを提供し、彼女のセーラーカラーのクールな青との補色対比を作り出しています。素材感は、滑らかでほぼ磁器のような肌、柔らかく流れる髪の毛、そして彼女の白いシャツとプリーツのネイビーのスカートのパリッとした、しかししわのある質感によって表現されています。ラバーダックは滑らかでマットな仕上がりを示し、水たまりの非常に反射的で濡れた外観とは対照的で、鮮明で光沢のあるハイライトを示しています。雰囲気は、深い静寂に繊細なメランコリーまたは静かな内省が混ざり合っています。キャラクターの閉じられた目と横たわった姿勢は、休息または引きこもりの感覚を呼び起こし、ラバーダックの遊び心のある存在は、無邪気で、ほとんど夢のような、非現実性の層を追加しています。このシーンは親密で静かで、静かな瞑想を誘います。"
}
},
"wd_tagger": "1girl, solo, long_hair, looking_at_viewer, bangs, skirt, blonde_hair, shirt, long_sleeves, bow, school_uniform, purple_eyes, white_shirt, pleated_skirt, lying, parted_lips, serafuku, bowtie, pink_eyes, sailor_collar, water, red_bow, blue_skirt, bird, on_side, blue_sailor_collar, rubber_duck",
"wd_tagger_metadata": {
"character": [""],
"series": [""],
"artist": [""],
"rating_tag": ["safe"],
"quality_tag": ["master piece"]
}
}
Data Processing
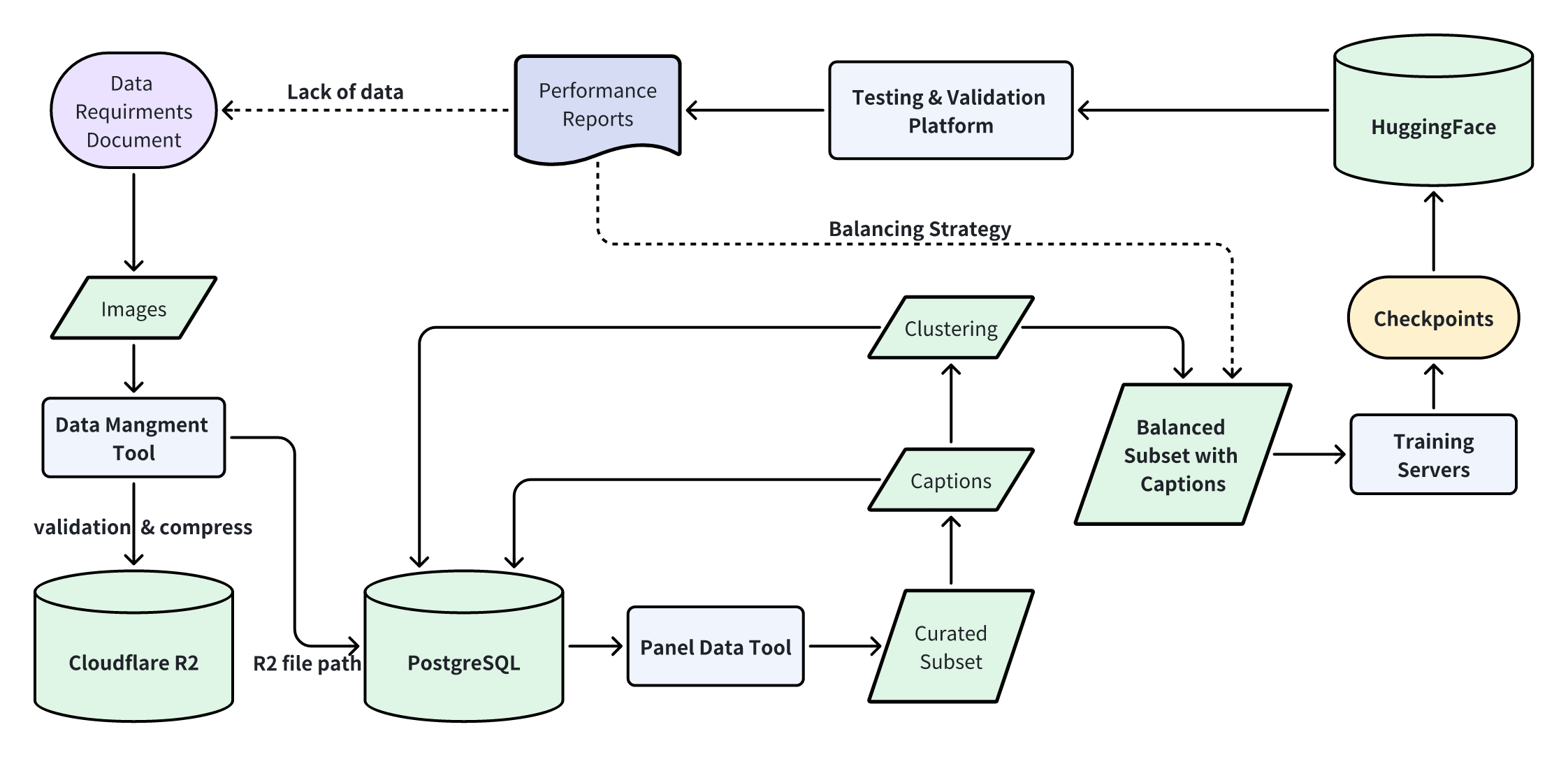
Data Management Tool
Uploading datasets, collections, and caption tasks.
Panel Data Tool
Convenient preview, manual labelling, and filtering interface. Shares data source with Data Management Tool.
Testing & Validation Platform
Systematic comparison via large-scale controlled variable experiments.
Training Configuration
4 servers, each equipped with 8 NVIDIA A100 GPUs
84,000+ A100 GPU hours in total
Ⅶ. Limitations
There are some checkpoints performing better on certain styles and concepts. We picked this specific checkpoint as release because it achieves the overall best on
-
Knowledge
-
Aesthetic
-
Limbs & hands details
-
Style diversity
-
Prompt adherence
We understand that Neta Lumina has a relatively high demand for hardware, and we are working with community to build better Lumina ecosystem. Any support is truly appreciated.
Ⅷ. Future work
-
Open source captions
- Open source caption prompts & scripts
-
Lossless inference acceleration
-
Coverage optimization
Ⅸ. Open-Source & Licensing Plan
Neta Lumina is released under Apache License 2.0
Ⅹ. Participants & Contributors
Special thanks to the Alpha-VLLM team for open-sourcing Lumina-Image-2.0
-
Model development: Neta.art Lab (Civitai)
- Core Trainer: li_li Civitai ・ Hugging Face
-
Partners
-
nebulae: Civitai ・ Hugging Face
-
生姜: Hugging Face
-
孙一
-
-
narugo1992 & deepghs: open datasets, processing tools, and models
-
Aesthetic models
Community Contributors
Evaluators & developers: 二小姐, spawner, Rnglg2
Other contributors: 沉迷摸鱼, poi, AshenWitch, 十分无奈, GHOSTLX, wenaka, iiiiii, 年糕特工队, 恩匹希, 奶冻, mumu, yizyin, smile, Yang, 古神, 灵之药, LyloGummy, 雪时
Ⅺ. FAQs
-
Why don't we rely solely on aesthetic-scoring models?
-
Model bias is inevitable. Score-distribution charts show that each scoring model favors certain visual patterns; using only models introduces systematic errors.
-
Human taste ≠ model judgment. Details that look “beautiful” to humans may be flagged as defects by a model. We therefore blend the outputs of two complementary models and then filter the results manually to build aesthetic datasets.
-
-
Why provide captions in multiple languages?
-
Serve the core user base. Although Gemma supports a multilingual embedding space, it struggles with niche anime terms. We fine-tuned on English, Chinese, and Japanese— the three dominant languages in the anime community—to capture domain-specific vocabulary.
-
Minimize semantic ambiguity. Prompting in languages the model isn’t trained on can result in output that's good but not 100% accurate. Multilingual training reduces mismatches and yields more predictable results.
-
-
Why support both natural-language and Danbooru-style captions?
-
Lower the entry barrier. Many creators are unfamiliar with Danbooru syntax; tag-only prompts can deter beginners.
-
Retain expert control. Experienced users still need fine-grained tags to steer composition precisely. By training on a mix of plain language and tags, Neta Lumina accommodates both casual “spoken” prompts and professional tag workflows.
-
-
Why did we choose to continue training from AES-1-e100 instead of RAW'-e7?
- We believe that adopting a training curriculum that alternates between large and small datasets (a “large-small-large-small” strategy) yields better overall model performance.
- AES-1 started as an additional experimental branch while we were training the RAW' branch to observe improvements in aesthetics. As we saw clear enhancements in aesthetics, we also noticed some knowledge degradation.
- Switching to AES-1 let us complete the final “large-small” stages and ship the best trade-off we could (stability, looks, short-prompt performance).
- If you are interested in training with more abundant GPU resources, RAW'-e7 checkpoint is a strong raw starting point.
Ⅻ. Appendices
We gratefully acknowledge the open-source community for providing the components listed below.
-
Inference Acceleration: Teacache